1. 基础知识
向量:即坐标系中的一个带方向的箭头, 包含:起点坐标、终点中标。
向量数据库: 即将一份数据转为向量,存储到数据库中,通过向量来快速检索。
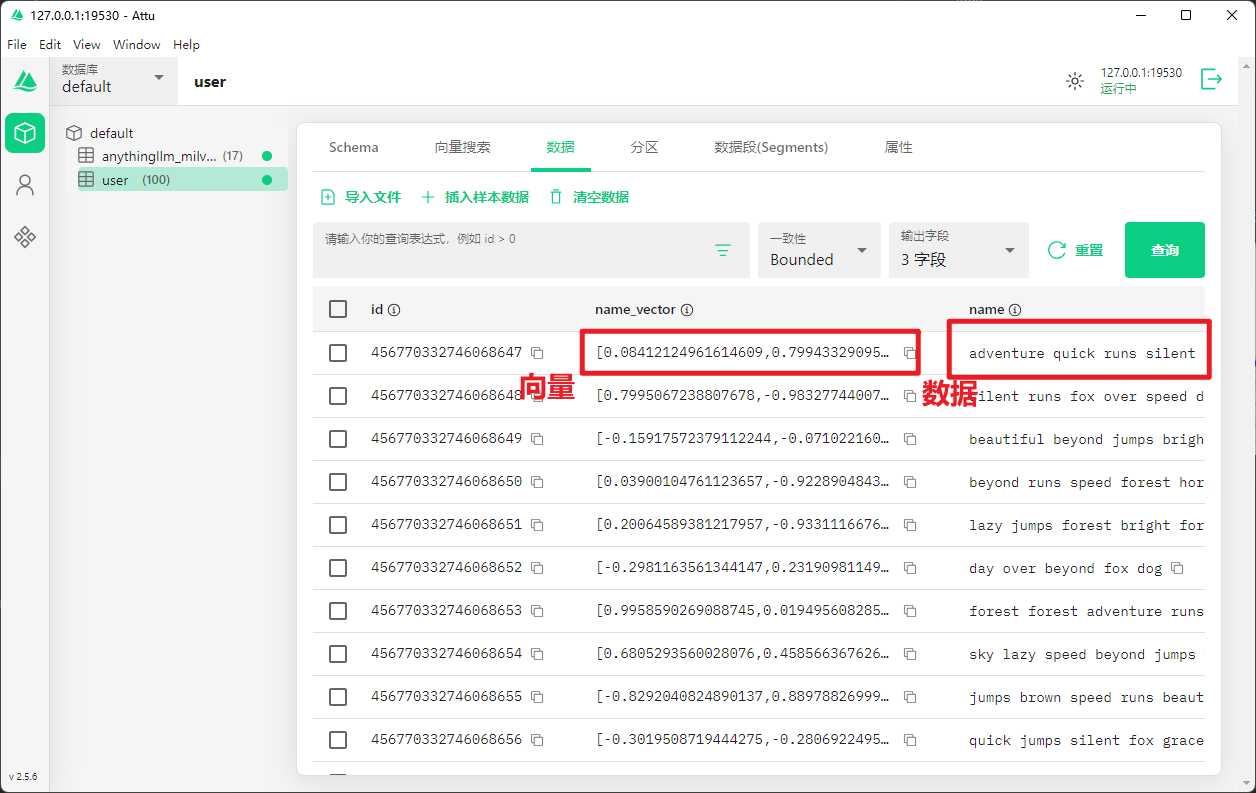
比如:绿色的树和绿色的草,他们是有一个相同的向量“绿色”,所以在AI搜索中,只要搜索绿色,就会将关联的数据搜索到。
向量数据库的应用:图搜图、文搜文、歌搜歌向量数据库的原理:- 转换:把文字/图片/音视频等信息转换为向量。
- 存储:将向量和数据保存到数据库。
- 搜索:用户搜索的时候,先把问题转换为向量A。
- 比较:计算向量A在空间坐标中特定距离内的所有值,去匹配比较。
- 返回结果:将相似度最高的结果返回。
向量Embedder:一种将离散对象映射到连续向量空间的技术,即将难以直接计算的数据(文字、图片、音视频)嵌入到一个数学问题中。
2. milvus
milvus的优点
答: 快、开源免费、容易使用milvus能做什么
答: 搜索图片、语音识别、推荐系统、智能问答milvus如何工作
答: 收集数据、保存数据、搜索数据milvus安装
答: 详见 AI知识库部署
3. attu使用
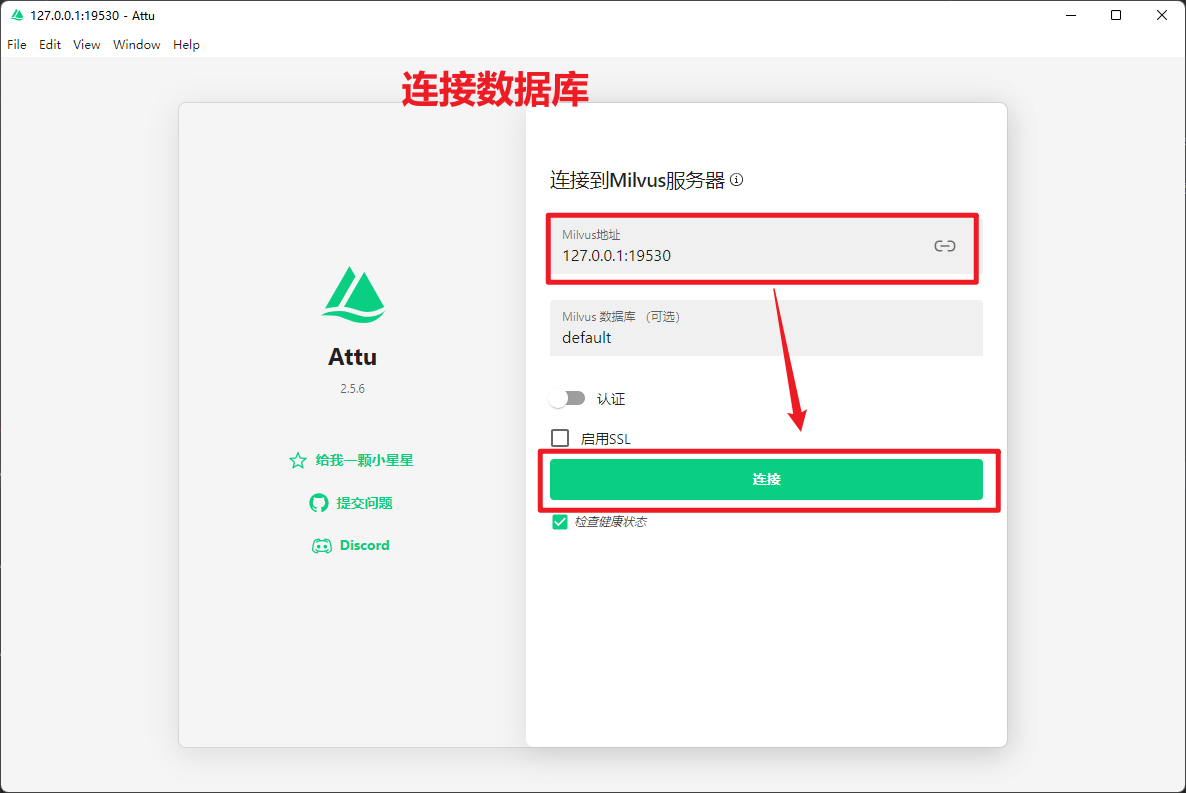
3.1 安装
详见 AI知识库部署
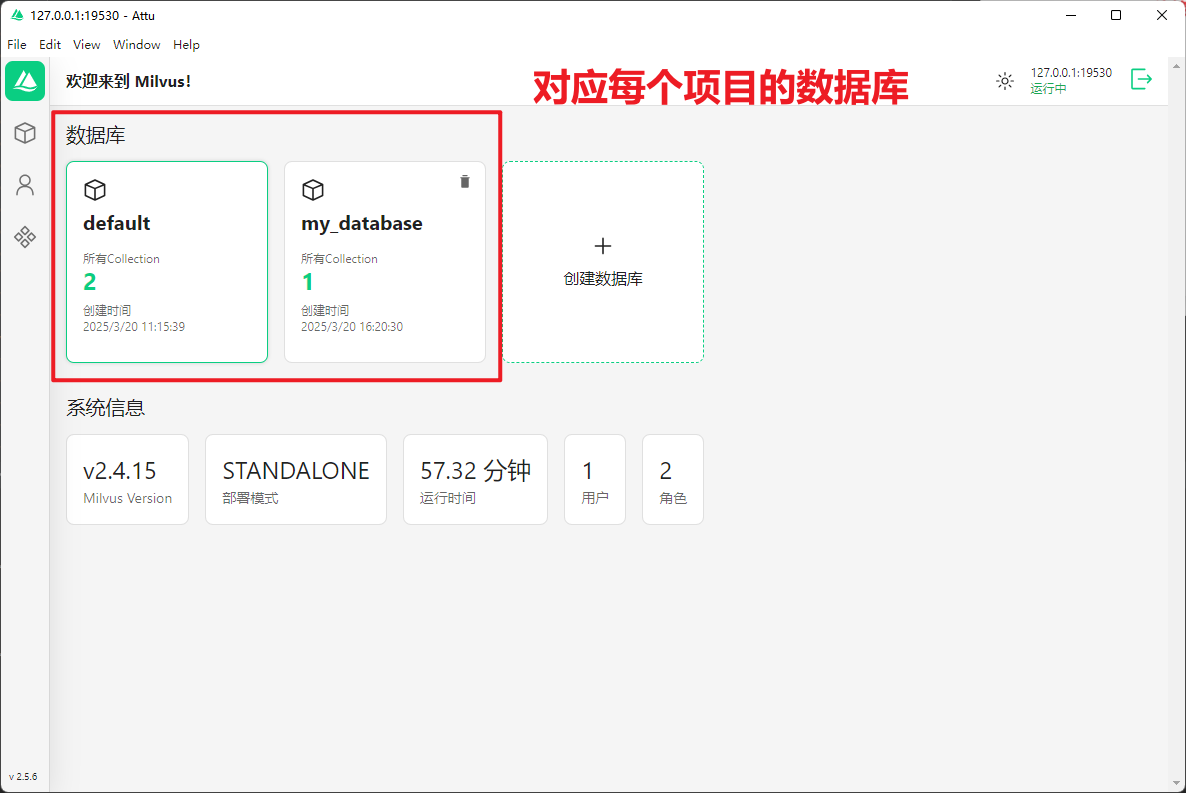
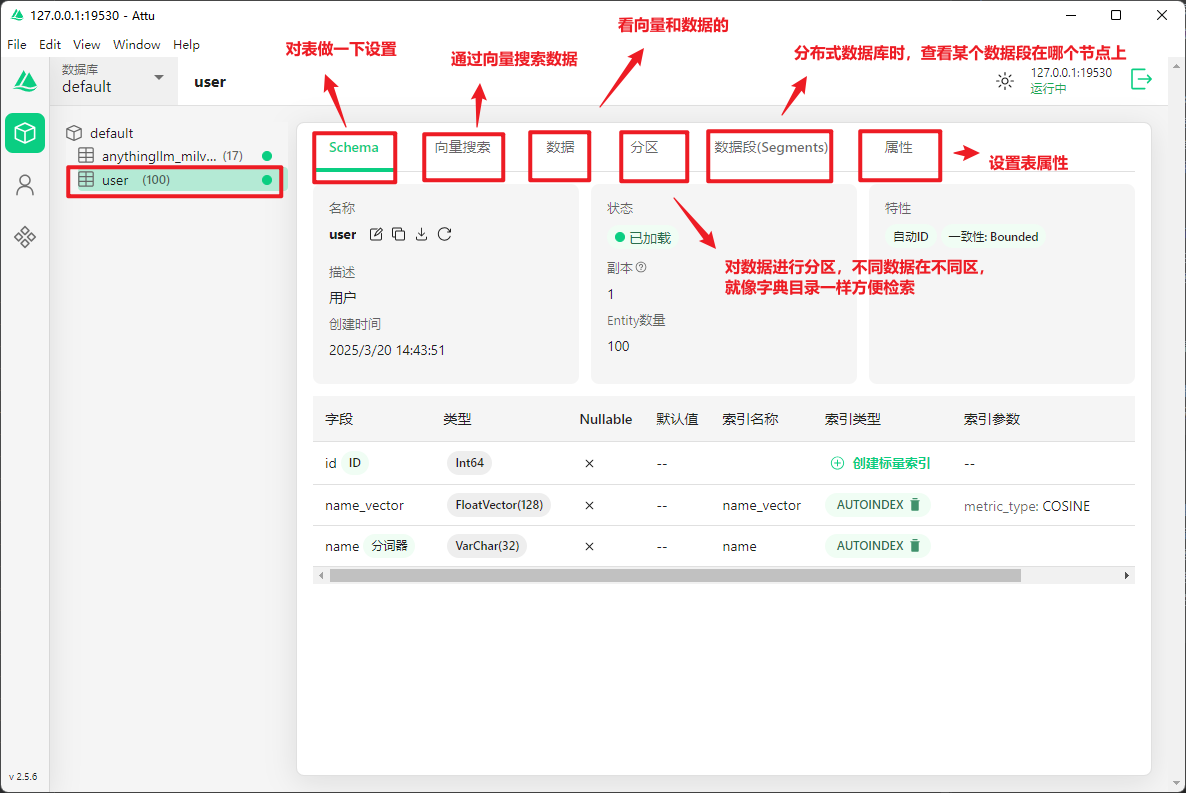
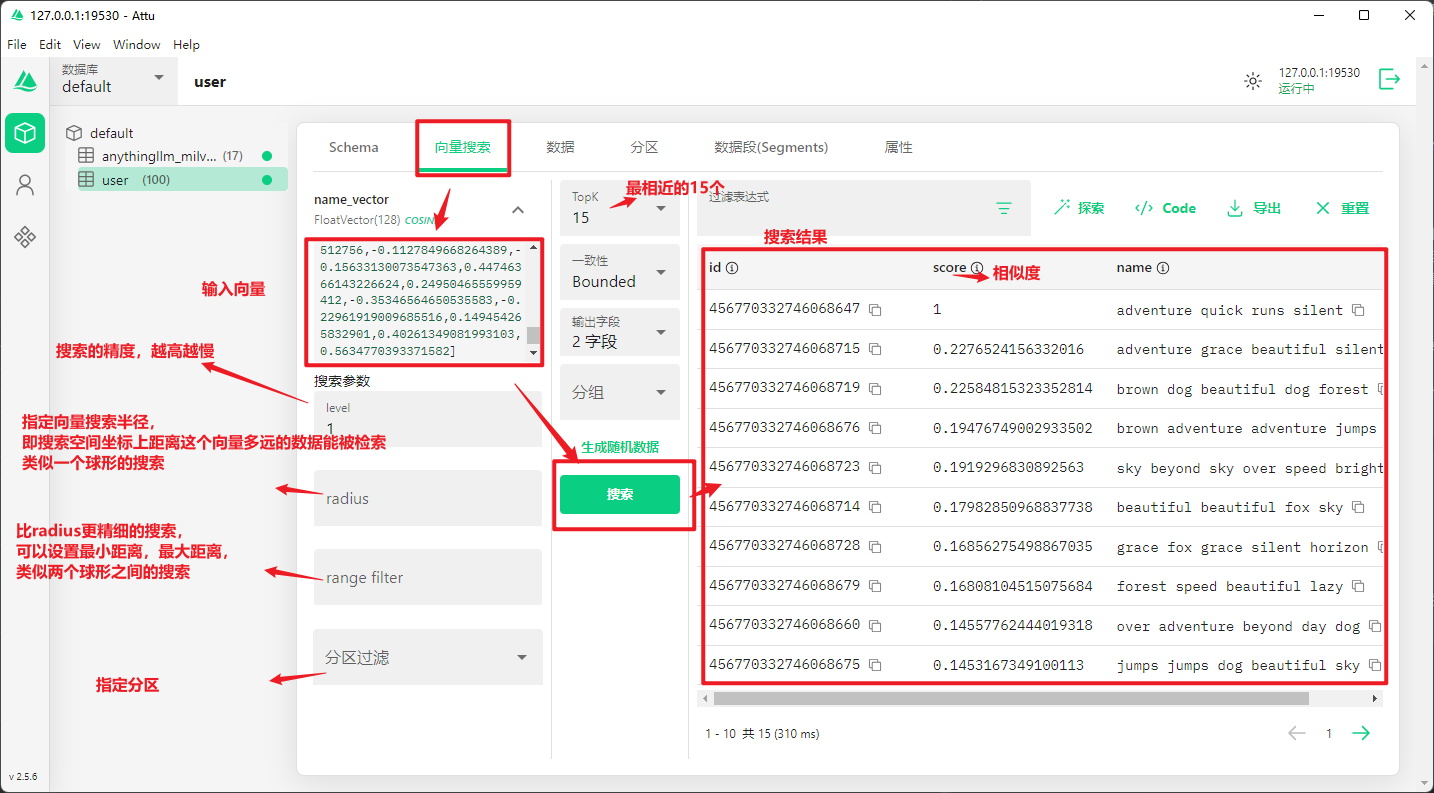
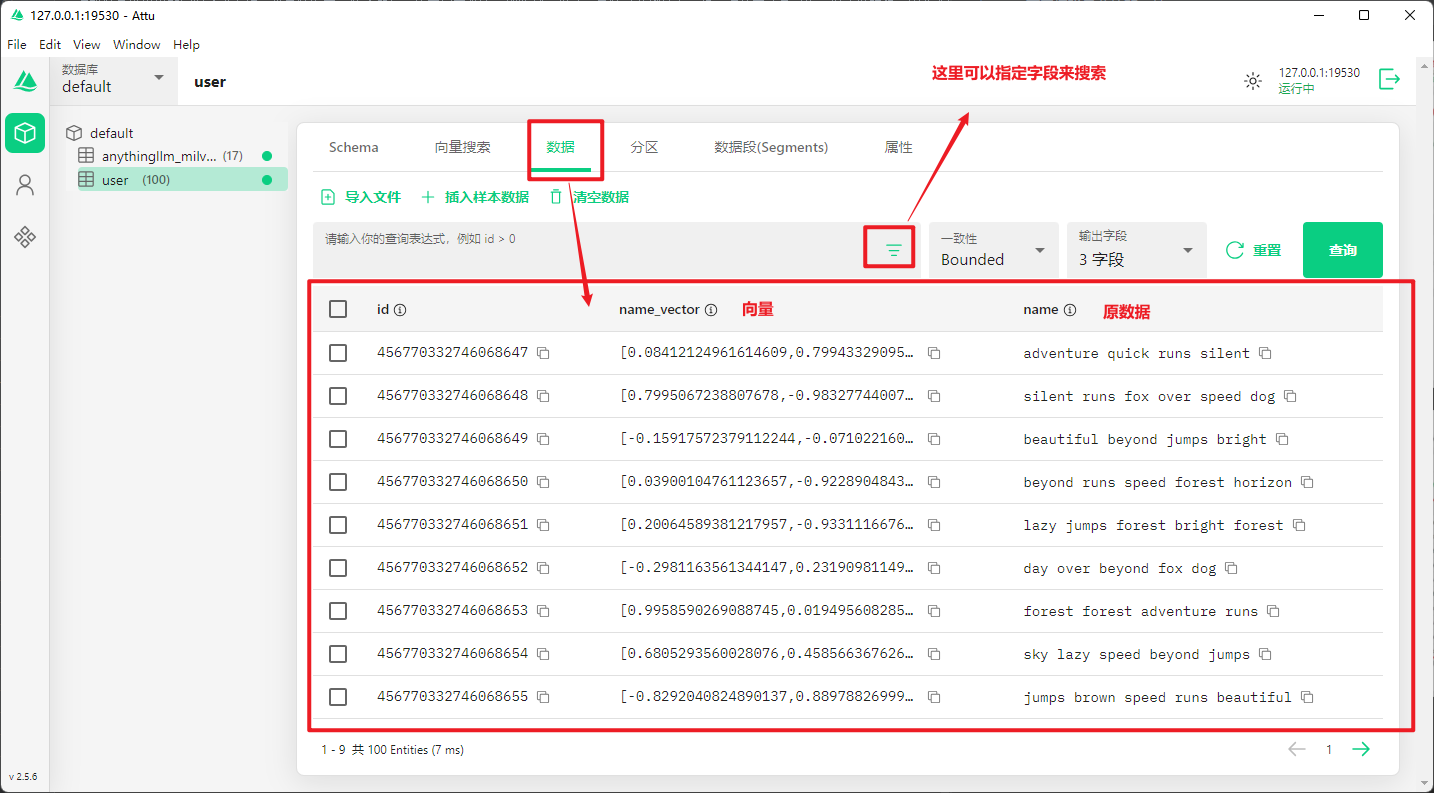
3.2 界面说明
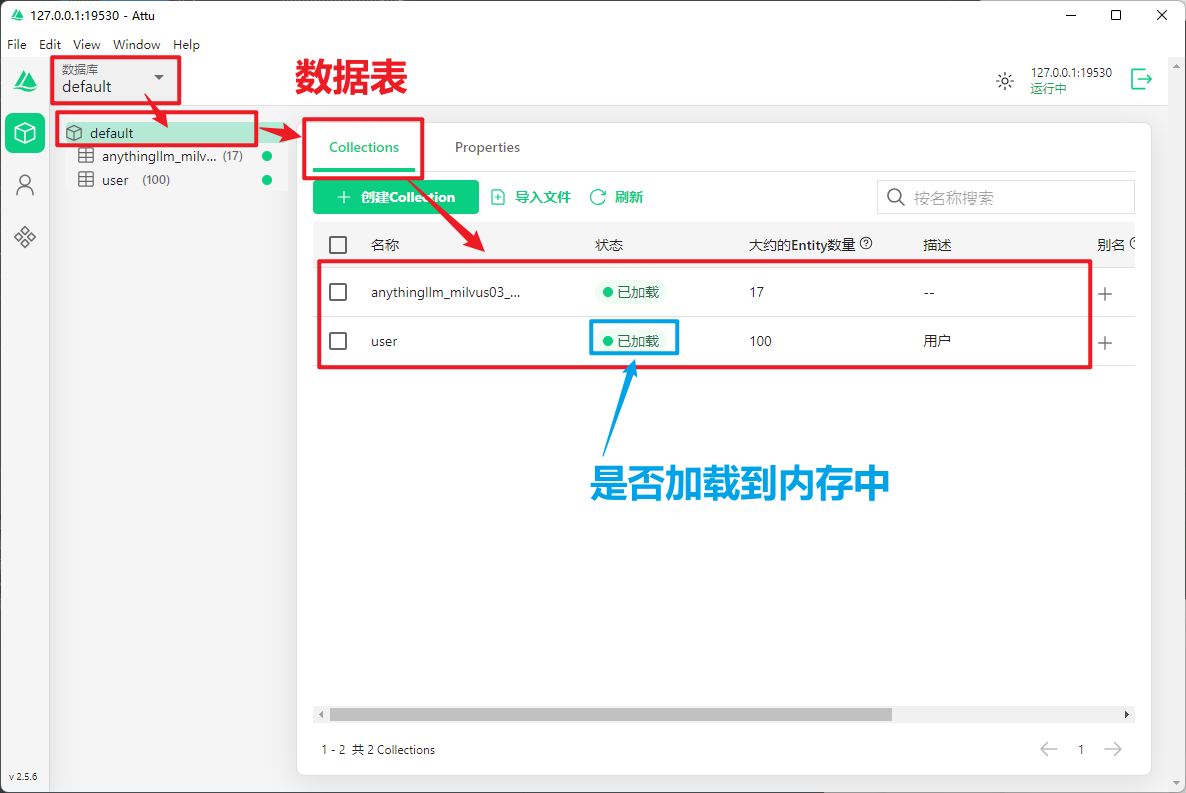
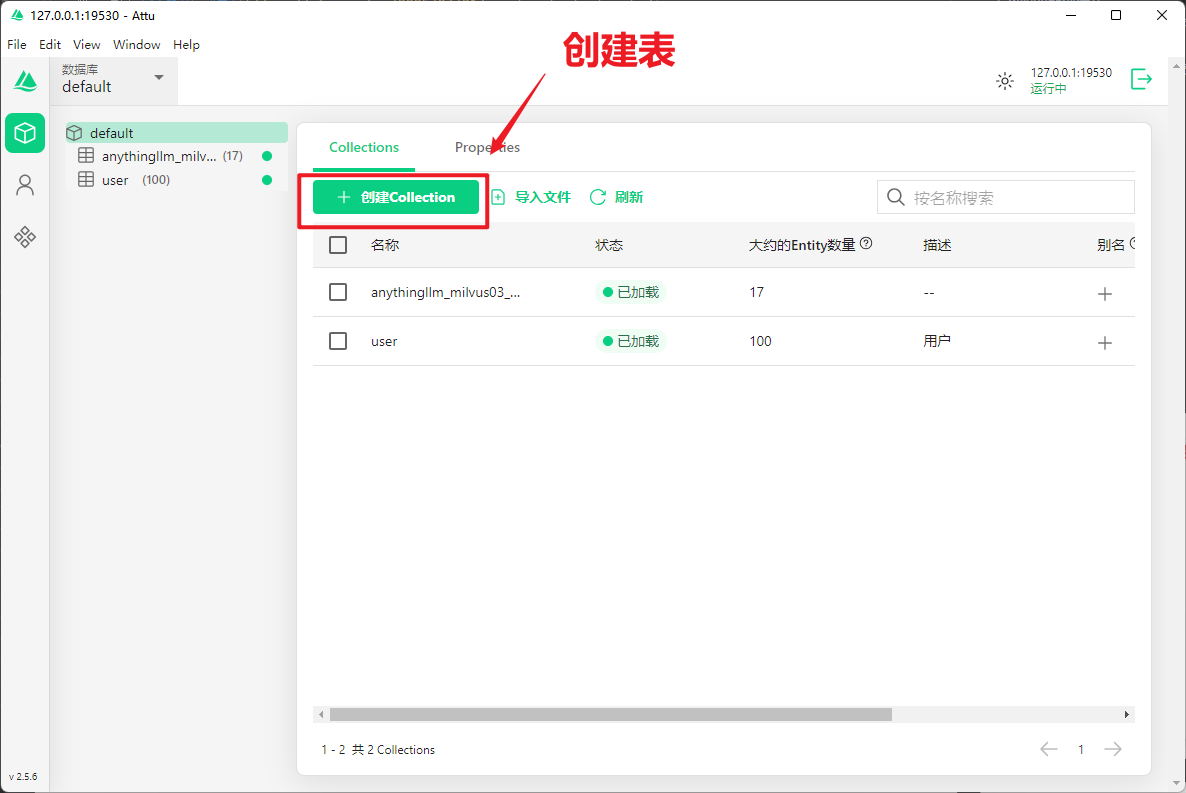
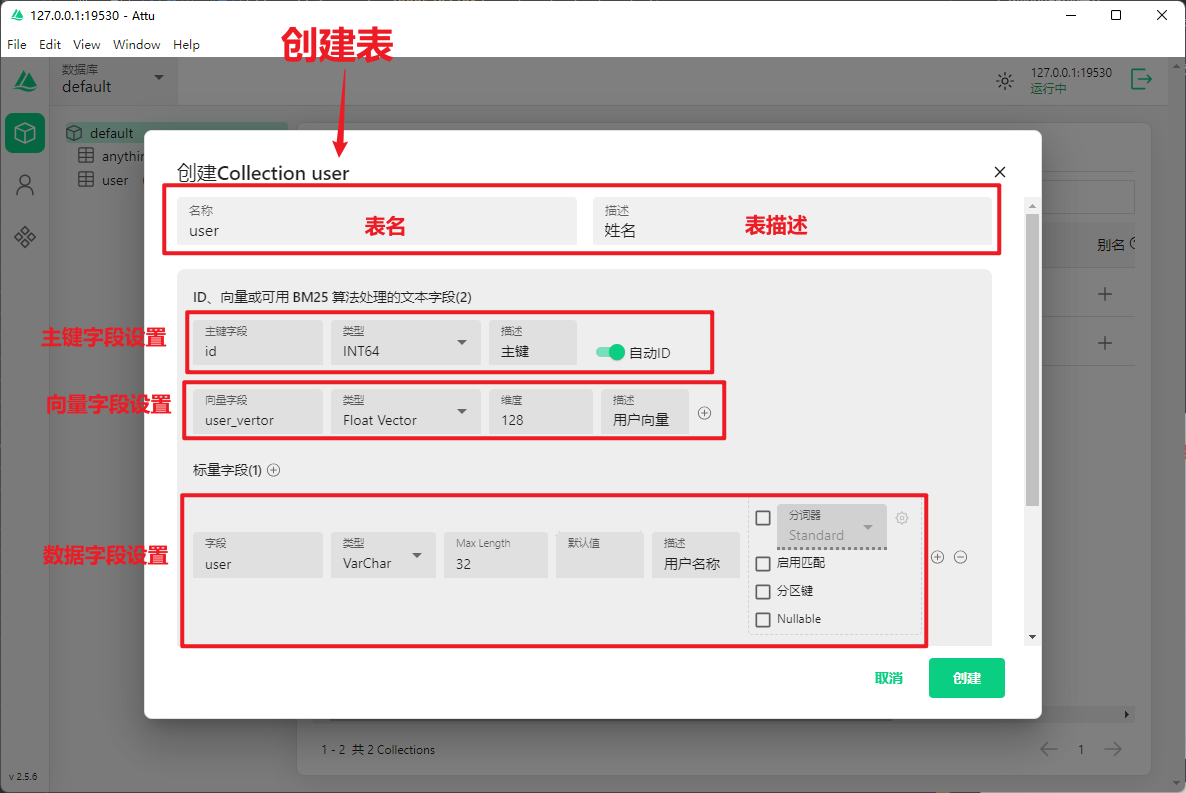
● 分词器 (Standard)
分词器是用来将文本分解成单个词语的工具。比如”我喜欢编程”可以被分解为”我”、”喜欢”、”编程”。Standard分词器是最基本的分词方式,它按照一定规则把文本切分成词语,这样在搜索时就能更准确地找到包含特定词语的内容。
● 启用匹配
启用匹配功能让数据库可以进行相似度查询。比如当你搜索”电脑”时,也能找到包含”计算机”的记录。 这就像是你在搜索引擎中输入关键词,即使不是完全一样的词,也能找到相关内容。
● 分区键
分区键用来将大量数据分散存储在不同的服务器上。 想象一下,如果你有一本很厚的字典,可以按照字母A-Z分成26个小册子,这样查找时就不用翻整本书了。分区键就是决定数据应该放在哪个”小册子”里的标准。
● Nullable
Nullable表示这个字段可以为空。就像填表格时,有些项目是必填的(不能为空),有些是选填的(可以为空)。如果勾选了Nullable,就意味着这个字段可以不填写任何值。
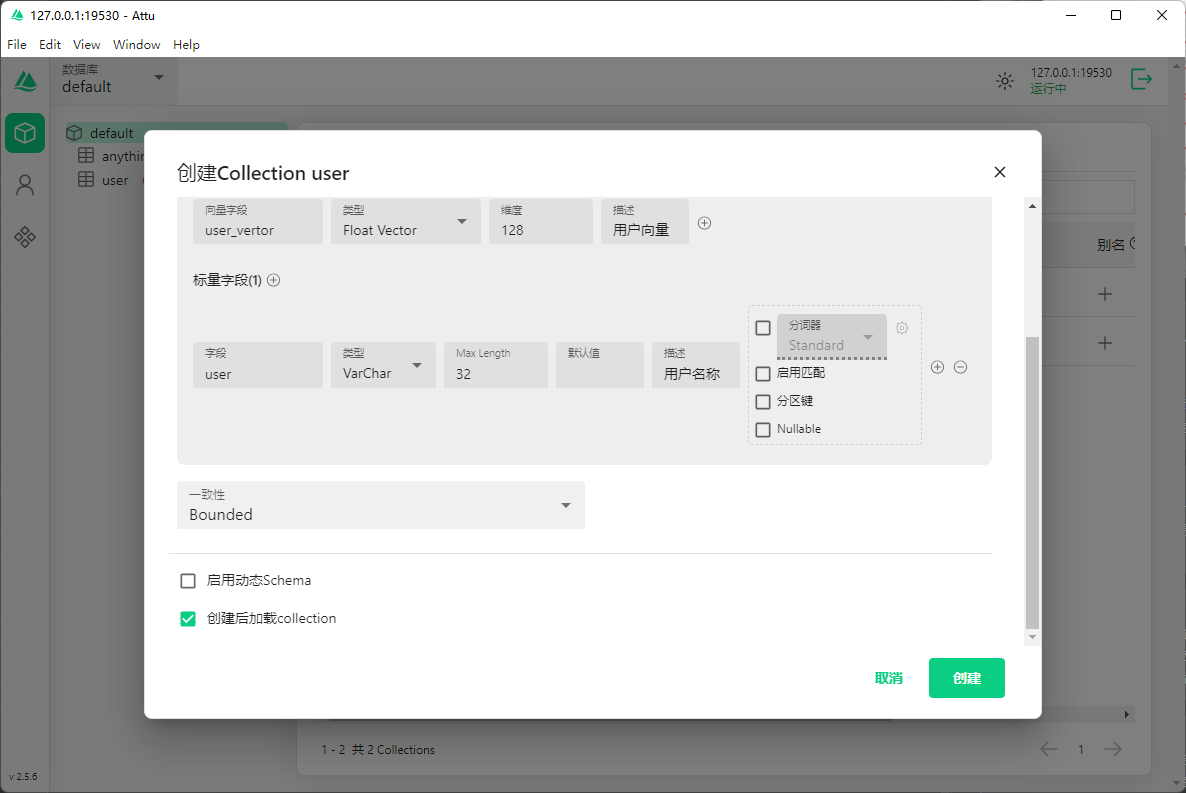
● 一致性 (Bounded)
Milvus创建集合时的四种一致性选项:
- Strong(强一致性)
这就像是班级里的实时通讯系统。当老师发布一条通知后,所有同学必须立即收到并确认,老师才会继续下一步。这种方式最可靠,但速度较慢,因为要等待每个人都确认。
例子:小明存了100元到银行,如果使用强一致性,那么无论他在哪个ATM机查询,都能立即看到准确的余额。- Session(会话一致性)
这像是你和好友的私聊。你发的消息,你的好友一定能按顺序收到,但其他同学可能暂时看不到或顺序不同。
例子:小红在网上商城下单后,在她自己的账号中能立即看到订单信息,但商城的总销量统计可能要稍后才会更新。- Bounded(有界一致性)
这像是学校的公告栏。老师贴出通知后,同学们会在一定时间内(比如10分钟)都能看到,但不要求立即。
例子:小华发了一条朋友圈,系统保证在5秒内,他的所有好友都能看到这条动态,但不一定是同一时刻看到。- Eventually(最终一致性)
这像是口口相传的消息。信息最终会传到每个人那里,但可能需要较长时间,且不保证具体何时。
例子:图书馆新增了一本书,系统会在某个时间点更新书目清单,但不保证具体何时完成,可能是几分钟,也可能是几小时。
如何选择?
- 需要数据绝对准确时(如银行交易)→ 选Strong
- 需要用户看到自己操作的结果时 → 选Session
- 需要在一定时间内保证一致性 → 选Bounded
- 对时间要求不高,但希望系统运行更快 → 选Eventually
- 不同的一致性选项就像是在”速度”和”准确性”之间做平衡,根据你的实际需求来选择最合适的一种。
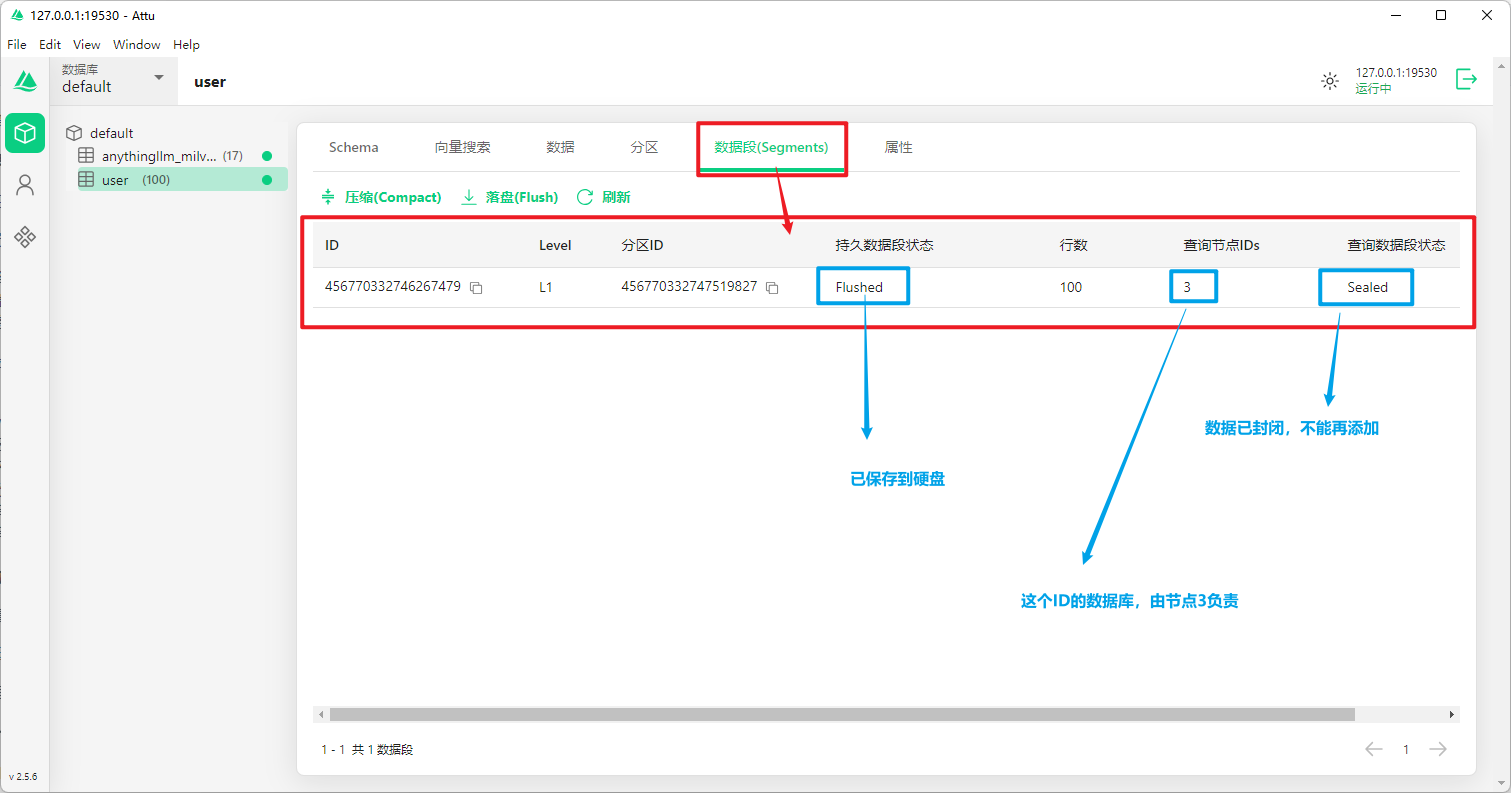
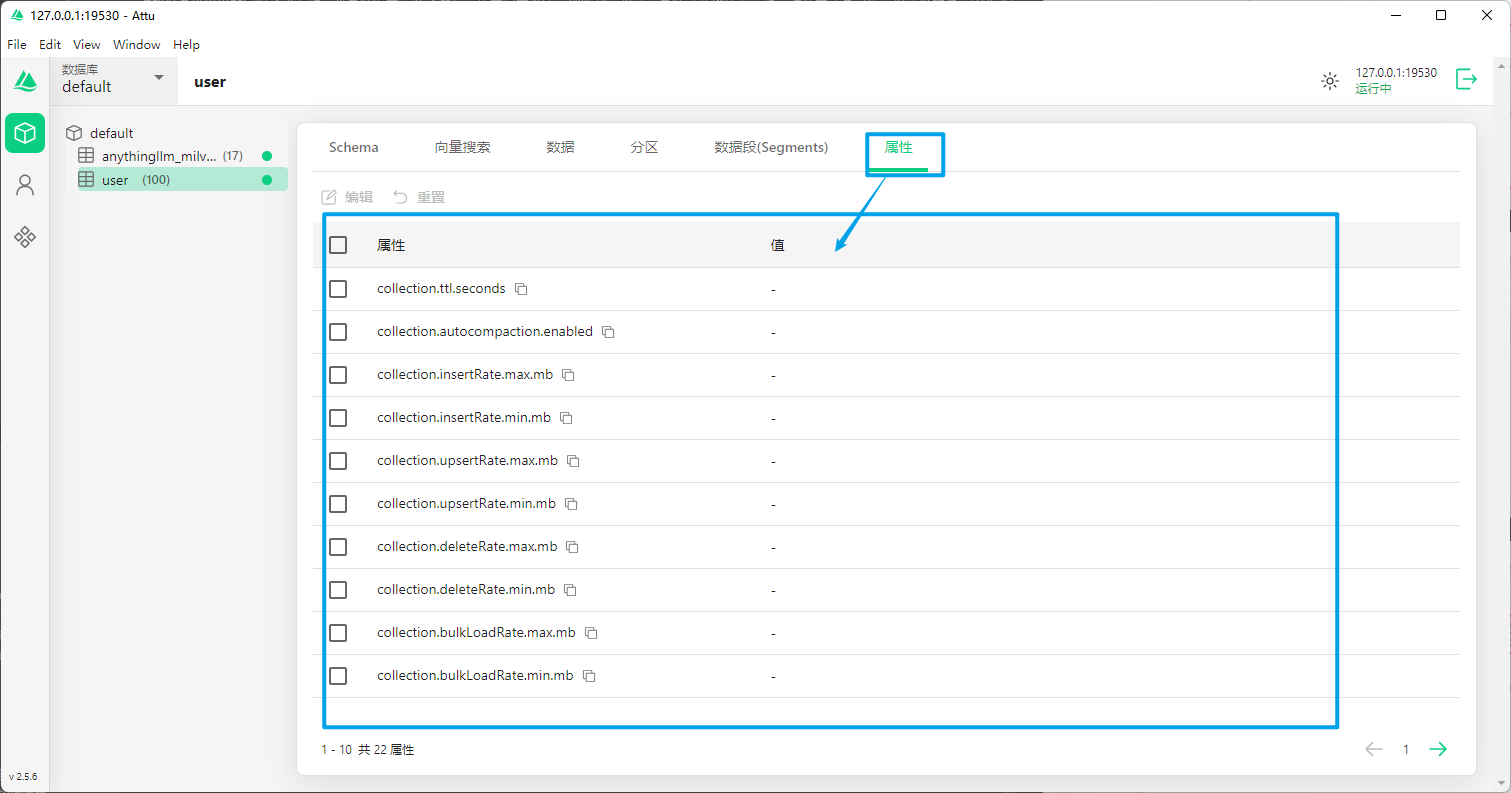
属性都以”collection.”开头,表示这些是针对当前集合的设置:
- collection.ttl.seconds
这是”生存时间”设置,决定数据在集合中保存多长时间
如果设置了这个值,超过这个时间的数据会被自动删除
- collection.autocompaction.enabled
控制是否启用自动压缩功能
压缩可以减少存储空间并提高查询效率
- 数据操作速率限制:
collection.insertRate.max.mb 和 min.mb:插入数据的最大和最小速率
collection.upsertRate.max.mb 和 min.mb:更新插入的最大和最小速率
collection.deleteRate.max.mb 和 min.mb:删除数据的最大和最小速率
collection.bulkLoadRate.max.mb 和 min.mb:批量加载的最大和最小速率
- 查询速率限制:
collection.queryRate.max.qps 和 min.qps:普通查询的最大和最小每秒查询数
collection.searchRate.max.qps 和 min.qps:向量搜索的最大和最小每秒查询数
- 资源管理:
collection.diskProtection.diskQuota.mb:磁盘配额,限制集合可以使用的磁盘空间
collection.replica.number:副本数量,用于数据备份和负载均衡
collection.resource_groups:资源组设置,控制集合可以使用的计算资源
3.3 node操作milvus
点击 代码 下载



